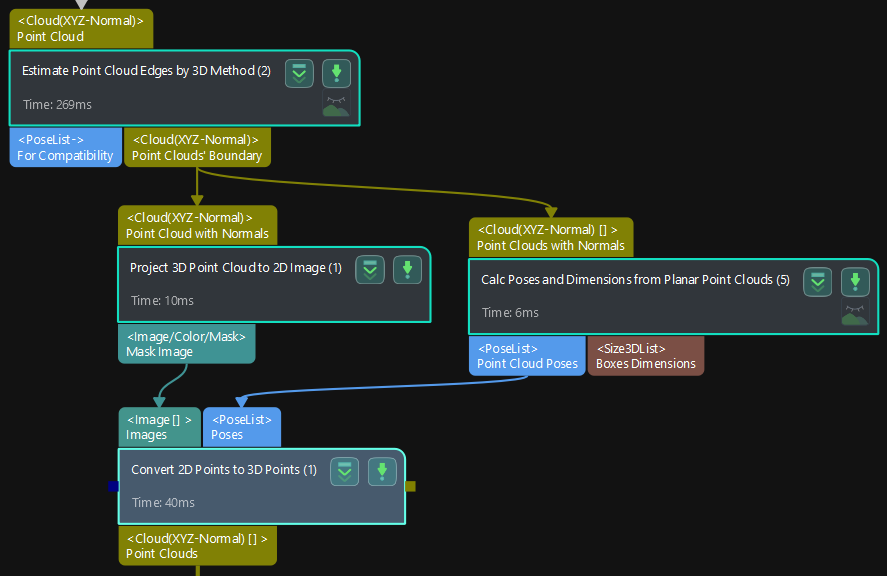
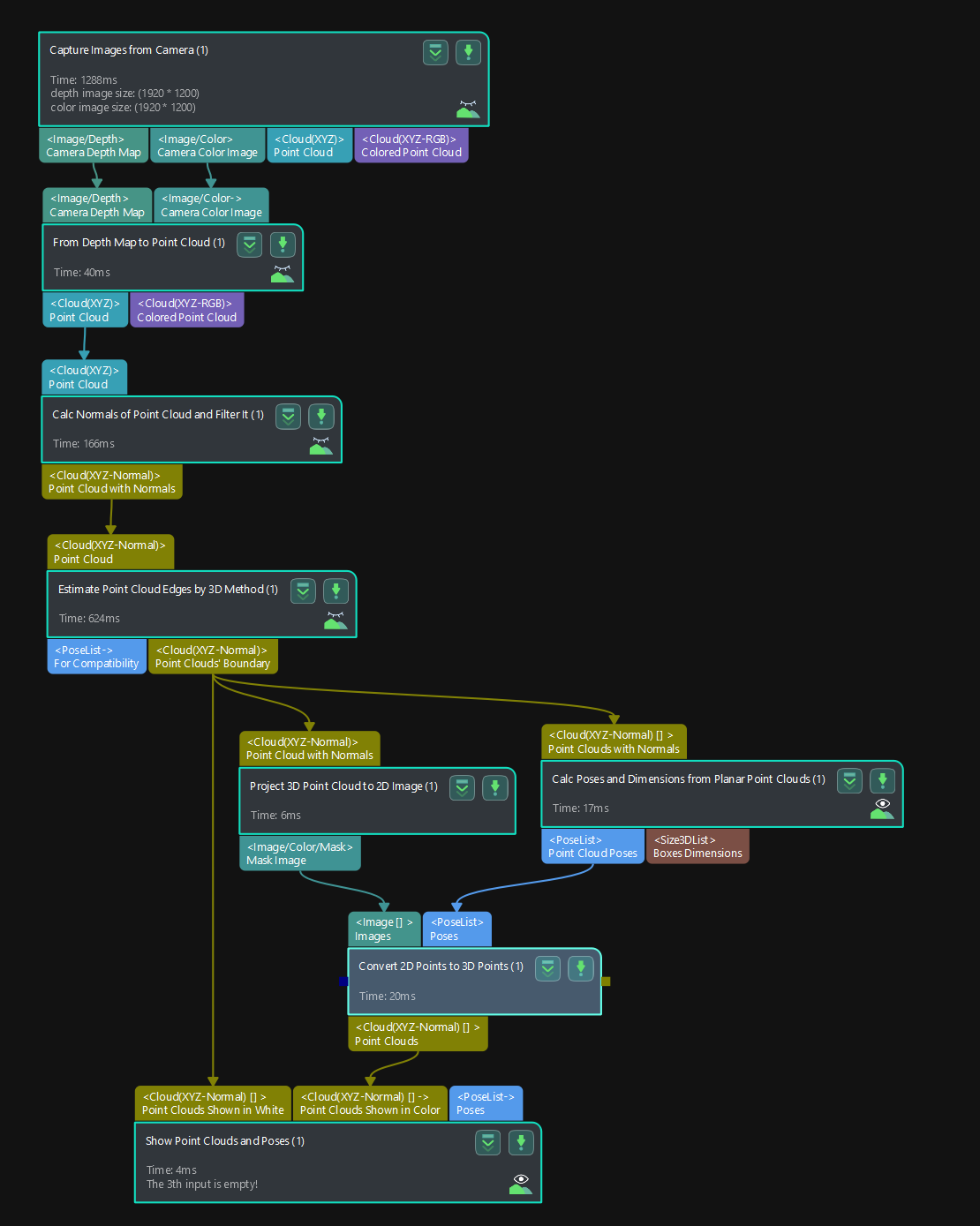
I was looking through example projects and found a step “Convert 2D Points to 3D Points”.
It takes as input a (mask) image and a Pose and outputs a Point Cloud (XYZ-Normal).
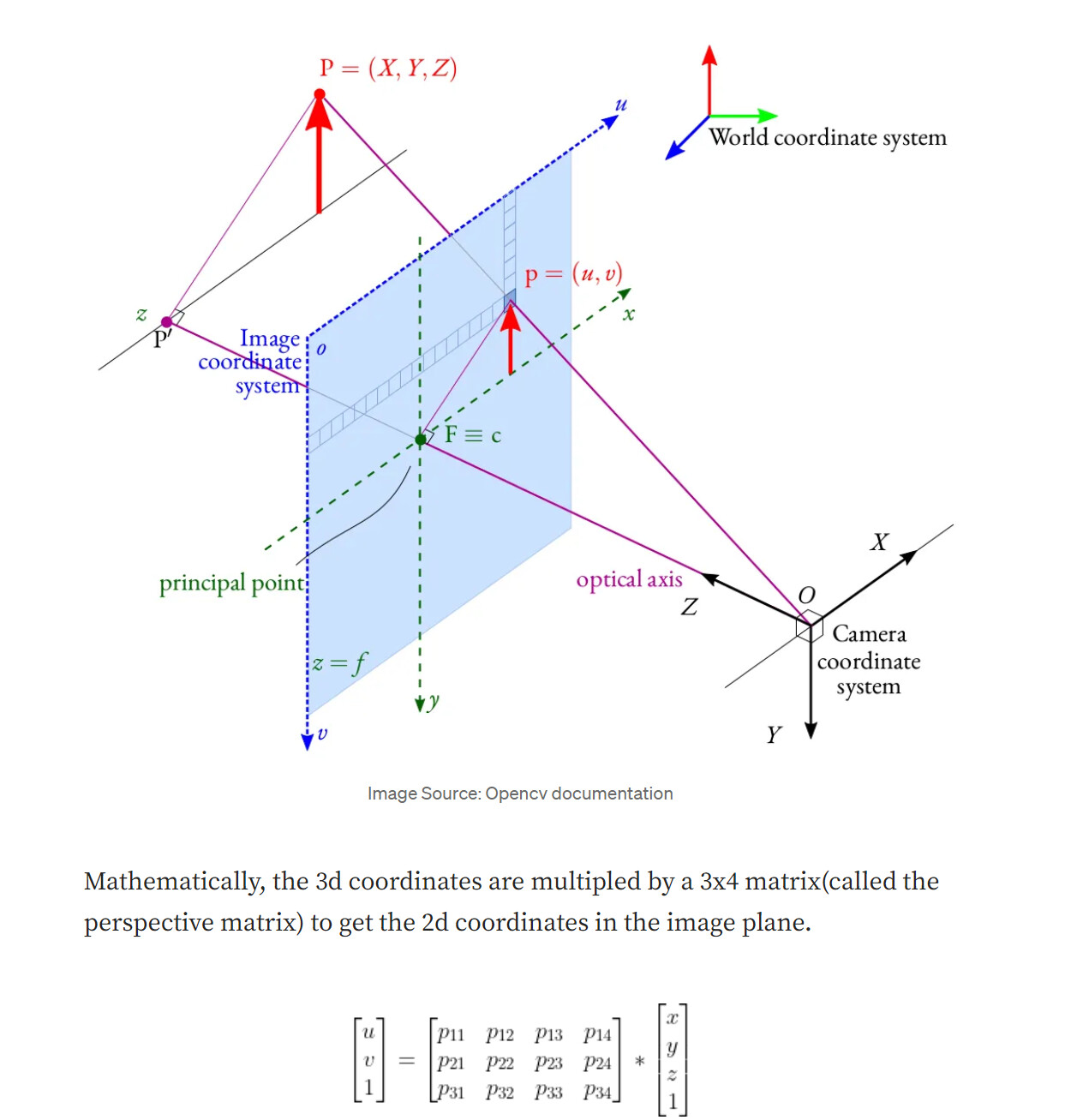
I am trying to understand how this step works internally. How can an image and a 3d pose be combined to get to a point cloud?
Can you please explain?
Is the image projected as a plane into the 3d world with the image center being at the pose center? But how is the size of the image plane scaled accordingly?
So the point cloud that is generated is always a plane?
Thanks. So the image, i.e. mask, is expected to be derived from “Perspective Projection” from the point cloud in camera coordinates and the pose is the center of the point cloud.
For what objects can I use this step?
I assume that this step is only meant to be used for flat surfaces and only for a single object at once?
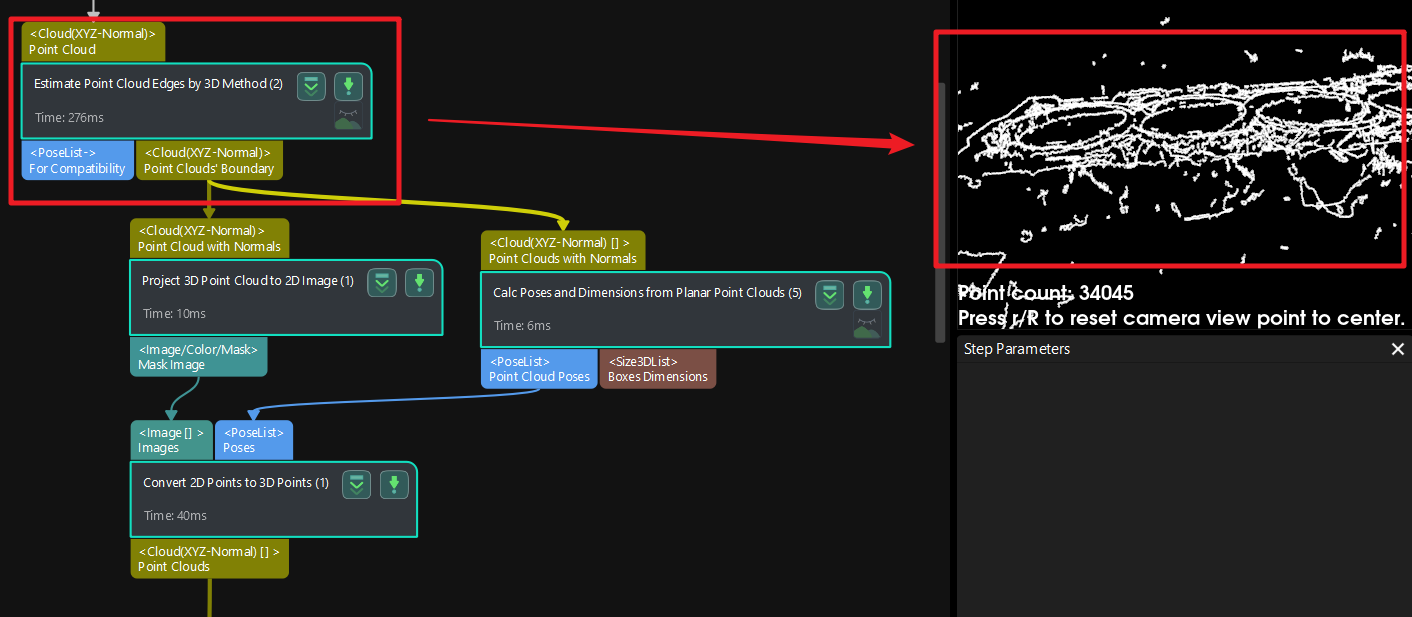
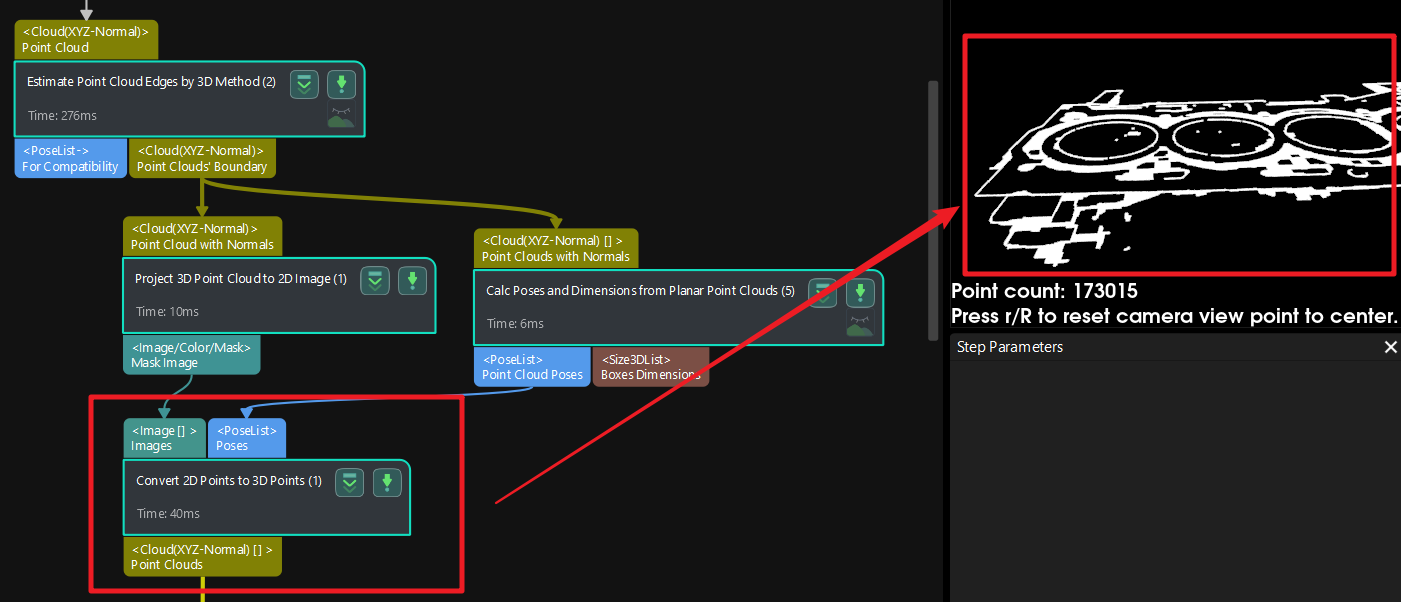
I tried this step naively (on purpose) for a whole and filled KLT:
For my understanding, how are the mask image and pose combined to get a point cloud? Using an inverse pinhole model (and distortion model)? How is the pose orientation taken into account?
I assume a distortion model is also used since when I set my pose orientation manually to e.g. 45° then my point cloud plane looks like a parabola from the side.
“The understanding is correct. This step only applies to planar point clouds. A segmentation algorithm (such as deep learning or clustering) can be used to segment out the planar point clouds first.”